
AI agents are a big change. First, these systems work by themselves. In other words, they can think, plan, and do hard tasks. They use outside tools. Thus, agents can automate complex work. This work was for human experts only. However, businesses face one big problem. Specifically, they need agents that work well and are safe. Bad agents waste time and money. Clearly, they give users a poor experience.
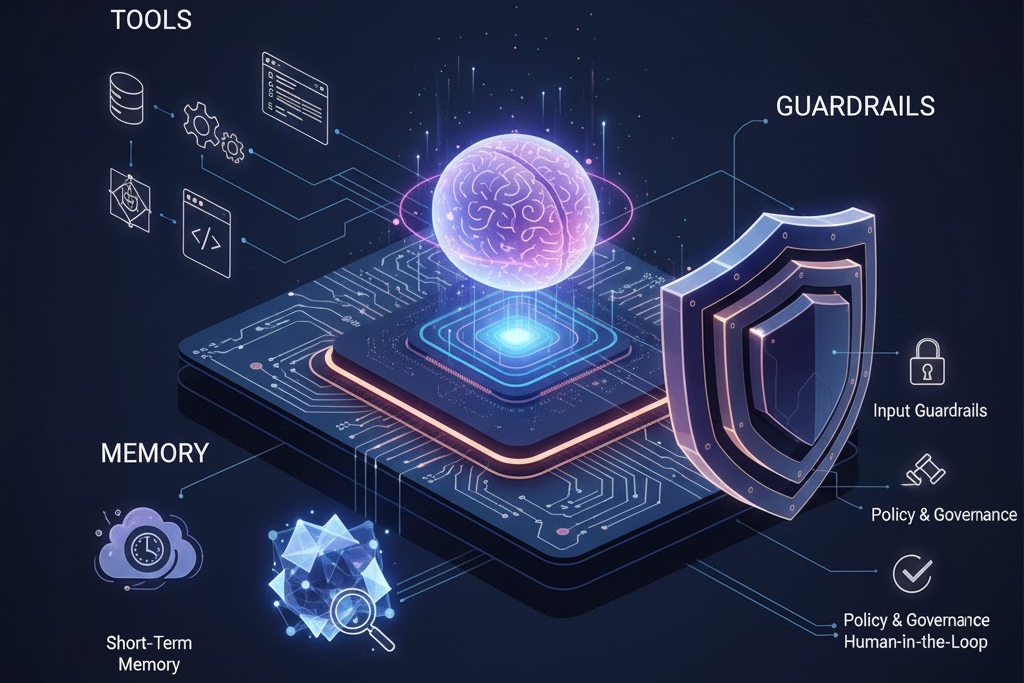
Furthermore, safety mistakes cause huge risks. Therefore, we must use a good company AI structure. We must also use proven design ideas. Chiefly, these ideas focus on tools, memory, and clear safety rules. Consequently, this story looks at these three main parts. They help build very trusted AI agents. These agents can handle real company jobs.
Companies often start with simple tasks. Generally, they test AI agents this way. Yet, real business processes are complex. They need agents to check many systems. Also, agents must make hard choices. They must follow strict rules. As a result, an error at any stage can fail the work. The agent may invent a fact. It could call the wrong tool. In fact, it might forget a key step. This failure stops many companies. Indeed, they do not widely use agents. Moreover, the way large models work is not always clear.
For this reason, finding and fixing errors is very hard. Thus, we must use design plans to add structure. This makes agent work easy to predict. Above all, this is how we fix bad agents. The agent stays flexible. Its main actions stay real and easy to check. They are always within the company’s AI rules.
A large language model is a strong brain. However, an AI agent must act in the real world. Tool use gives the agent this power. To clarify, this means it can use APIs, databases, or code. Tools are the agent’s hands. Put simply, they let it do tasks the brain cannot do alone. Tools check the weather. They update a customer’s record.
In contrast, how you design the tool integration greatly affects how well agents work. It also prevents the agent from making up facts. Therefore, use clear tools for each job. This is key for safe agent design. Do not rely on the brain’s internal facts. Specifically, split outside actions into separate jobs. This makes the brain’s choices simpler. Hence, the whole workflow becomes much stronger.
The tool-call pattern is the best design for tools. To begin, it is the most common one. This plan gives the AI agent tool lists. The list has clear tool descriptions. For example, these tell the model what each tool does. They list the data it needs. A tool is, for instance, get_order_status(customer_id).
The agent’s thinking part gets a user’s request. Then, it picks the right tool to call. It finds the needed data. It plans the steps. Next, the system runs the tool. The result is new data. This data is a fact, a success, or an error. Ultimately, this new info goes back to the agent’s brain. Clearly, this loop is: “Think → Call Tool → See Result → Think.” This is the ReAct process. Therefore, ReAct gives a method for long, multi-step tasks.
This plan gives big gains. On one hand, it greatly cuts down on made-up facts. The brain makes a sharp, structured tool call. Conversely, it does not make up a sentence. It picks from a menu. It does not invent actions. On the other hand, it keeps roles very clear. The LLM does the thinking. The external tools handle the actions. They do real, sure work. As a result, this setup makes the agent’s moves easy to track. They are simple to fix. Thus, this directly helps to stop bad agents. In addition, agents can use existing company tools. They do not need to relearn company data.
A good agent must remember talks. It needs context across many sessions. Otherwise, every user talk begins new. A service agent that forgets the last five minutes fails. Therefore, this need for memory demands a smart agent memory plan. This plan must go beyond the model’s small memory limit. Good memory is vital for personal tasks. It is also key for long-term facts and history. Indeed, without an outside memory, agents fail hard tasks. These tasks rely on old talks. They need access to large company facts.
A key memory plan is to separate short memory from long memory. In contrast, using all context the same way is a mistake.
The RAG pattern is key for the agent’s long memory. RAG means Retrieval-Augmented Generation. First, when the agent gets a query, it asks its long memory for the most useful facts. For instance, this might be documents, rules, or old talk summaries. Then, the agent puts this content into the prompt. This gives the model new knowledge. That is to say, it goes past the model’s small limit. This makes agent choices based on real, full facts.
In this way, the agent does not use only its general training. This is very important for finance or law tasks. Likewise, RAG allows the company to update agent facts fast. You just upload new files. Therefore, you do not need slow, costly model fine-tuning. This makes the company AI setup more quick.
An agent must act within clear limits. Its power must be tied to rules, ethics, and laws. Crucially, this is essential in a business. An agent must never enter banned systems. It must not share private data. It cannot break company rules. As a result, guardrails—clear, multiple-layer safety systems—are a must-have. They are key for lowering safety/compliance risk. Ultimately, they form the core of good rules for agents. Guardrails change an agent from a simple test into a trusted tool.
A truly secure agent needs many safety layers. It must check inputs and outputs. Therefore, relying on one defense will fail.
These safety rules must link to company rules for agents. Therefore, the Human-in-the-Loop (HITL) system is a key plan here. For example, for high-risk actions, the system sends the agent’s planned action to a human. This is for things like a big cost approval. A human expert reviews the action. They give the final OK. In this case, this pattern is necessary for safe agent design in banks or law firms. It creates a clear record. It ensures someone is held to account.
Furthermore, the agent setup must track every choice. It must log every tool use and rule check. This allows the review team to check the agent all the time. They can fix the rules for agents often. Consequently, this keeps the agent safe and always improving. The use of tools, deep memory, and layered rules makes a test model into a powerful, trusted, and safe company AI agent.
The risks include losing money from wrong actions. Examples are mistaken payments. Also, they include brand damage from bad content. They cause work failure when agents make up facts. Therefore, using strong design plans is vital to lower these risks.
Tools have clear lists of what they do. This guides the agent’s brain. The agent makes a sharp tool call. Instead, it does not write free-form text. This makes the action certain. It is based on a real system. Consequently, this greatly cuts the model’s habit of inventing facts.
RAG means Retrieval-Augmented Generation. For instance, for agent memory, the agent asks a special database for facts. This database holds company knowledge. It gives the model real info. This info goes into the prompt. In effect, it gives the agent long-term memory. This goes past the model’s own small input limit.
Prompt injection is a security hole. A user tries to trick the agent. They use bad input to make it break its own rules. Therefore, rules stop this with a ‘Prompt Shield.’ This shield checks the user’s input. It blocks or cleans the input before the model sees it.
Safe agent design must make sure the agent always follows three rules. Namely, these are: compliance (following laws), business policy (following internal rules), and security (stopping data leaks). We do this with output checks, safety rules, and good tracking.
Also Read: Custom GPT vs Off-the-Shelf: How to Decide, Build, and Measure ROI
